【新智元导读】刚刚,AlphaEvolve又上大分了!基于它的开源实现OpenEvolve,靠自学成才、自己写代码,直接在苹果芯片上进化出了比人类还快21%的GPU核函数!这一刻,是自动化编程史上真正里程碑时刻,「AI为AI编程」的新时代正式开启,自动化奇点真要来了。谷歌的AlphaEvolve,还在不断创造新的奇迹。在5月中旬,谷歌扔出的这个炸弹(号称是数学界AlphaGo的「第37步」时刻),就在不断冲击人们的认知——AI,已经拥有了自我进化能力!
随后,不断有开发者用代码证实,AlphaEvolve的矩阵乘法突破为真!一个开发者成功证明,它仅用了48次乘法,就正确完成了4×4矩阵的乘法运算。
而就在刚刚,patched.codes的联合创始人兼CTO Asankhaya Sharma,用基于AlphaEvolve论文的开源实现OpenEvolve,成功自动发现了高性能的GPU内核算法。

具体来说,通过自我进化代码,它自动发现了一套在Apple Silicon上远超手动优化的GPU Metal核函数。
在真实的Transformer推理任务中,它带来了平均12.5%的性能提升,峰值甚至飙升了106%。
这种提升,直接超越了人类工程师21%!

这个系统没有提供人类的GPU编程专业知识,就发现了以下优化——
· 完美的SIMD优化
· 两阶段在线Softmax
· 针对GQA的特定内存布局优化
这不是一次简单的性能跃迁,而是自动化编程历史上真正的里程碑时刻——一套系统无需人类干预,就能在复杂的硬件架构中,挖掘出连专家都难以察觉的优化路径。
更重要的是,这一成就并非停留在实验室或论文中,而是在真实世界中、在苹果芯片上、在当今最主流的AI模型任务中,扎实地跑了出来。
由此,就证明了自动化代码优化技术在真实世界系统中的实际可用性。
它标志着一个新的时代正在开启:不再是人类为机器手写优化,而是机器开始为自己写更好的代码。
而在之后,随着硬件架构持续高速迭代,OpenEvolve这种工具的价值还会愈加凸显——它们将发掘出那些仅凭人力极难找到的深度优化机会。
挑战:GPU核函数优化
为什么说,OpenEvolve攻克的这个「GPU核函数优化」,这么有挑战性呢?
这是因为,现代Transformer模型严重依赖于高度优化的注意力核函数,但编写高性能的GPU代码却需要具备以下领域的深厚专业知识。
·特定硬件架构的细节(如Apple Silicon的统一内存、SIMD单元)
·底层编程语言(如Metal Shading Language)
·数值算法设计(如注意力机制、数值稳定性)
·内存访问模式的优化
所以,是否有可能不用人写代码,完全交给OpenEvolve,让它自动进化,看是否能生成性能更强的GPU核函数代码?
为此,Sharma决定以Qwen3-0.6B模型的分组查询注意力(GQA)实现为目标,来检验OpenEvolve的能力,看它是否能自动生成超越MLX生产级的「scaled_dot_product_attention」核函数的代码。
具体来说,项目的目标配置如下。
· 模型:Qwen3-0.6B(40个查询头 : 8个键值头)
· 硬件:配备统一内存的苹果M系列GPU
· 基线:MLX的高度优化的注意力实现方案
· 挑战:全自动发现Metal核函数的优化方法
进化方法
Sharma将OpenEvolve配置为直接进化Metal核函数的源代码,同时保留其与MLX框架的集成方式。
整个系统从一个基础的三阶段注意力实现方案开始,历经超过25代的进化。
进化设置
max_iterations: 25 # 最大迭代次数population_size: 25 # 种群大小llm: primary_model:”gemini-2.5-flash” # 主模型:用于快速探索 (60%) secondary_model:”gemini-2.5-pro” # 辅助模型:用于深度优化 (40%)database: num_islands: 5 # 岛屿数量:用于并行进化多个种群evaluator: bulletproof_mode: true # 启用高强度GPU错误防护模式
评估策略
每一个通过进化生成的核函数都经过了以下维度的全面测试:
正确性验证:与MLX基线进行数值精度对比,确保计算结果无误。
性能测试:在20个多样化的推理场景(包括短/长上下文、生成任务)中进行基准测试。
安全性检查:包含GPU错误检测和Metal内存访问验证。
鲁棒性分析:通过多次重复运行进行统计分析,确保性能稳定。
关键优化
没想到,OpenEvolve在进化过程中,自主发现了以下几项体现出算法创新的优化策略!
1. 针对Apple Silicon的SIMD优化
// 进化前:逐元素标量运算for(uintd =0; d query_vec_v[HEAD_DIM /8]; // 对于128维的头,使用16个8元向量for(uintd_vec =0; d_vec *)(keys + k_base))[d_vec]);}
仔细看就会发现,OpenEvolve的一个亮点,就是自己发现了一个非常巧妙的优化——
对于128维的注意力头,如果把数据按8个一组来处理,刚好就能完美匹配Apple Silicon硬件的SIMD宽度。
这就相当于自动踩中了硬件的「甜点区」,完全不需要任何人工调优,就能把性能直接拉满,让硬件利用率最大化!
2. 两阶段在线Softmax(Two-Pass Online Softmax)
// Pass 1:在线计算最大值,用于数值稳定Tmax_score=T(-INFINITY);for(uintkey_pos=0; key_pos output_acc_v[HEAD_DIM /8];for(uintkey_pos=0; key_pos *)(values + v_base))[d_vec];}
在这个过程中,OpenEvolve做了一个很聪明的创新:把原来分开的两个步骤——Softmax归一化和值累加,融合到了一个计算循环中。
原本,传统算法要三个阶段才能跑完:先算注意力得分,再归一化,再加权求和。
现在直接两步搞定,流程更简洁,还大大降低了对内存带宽的占用,自然就跑得更快、更省资源了。
3. 针对GQA的特定内存布局优化
// 针对GQA的5:1查询头/键值头比例,进行直接映射constuintkv_head_idx = head_idx / HEADS_PER_KV; // 精巧的头映射逻辑// 实现合并内存访问模式constuintq_base = batch_idx * (NUM_HEADS * SEQ_LEN * HEAD_DIM) + head_idx * (SEQ_LEN * HEAD_DIM) + query_pos * HEAD_DIM;
在此处,OpenEvolve的创新点在于,专门针对Qwen3模型的特殊结构做了优化。
这个模型的查询头与键值头的比例是特有的40:8(即5:1),系统充分利用了这个特性,设计出一种独特的合并内存访问(Coalesced Memory Access)的模式。
这种模式,特别适合Apple Silicon的统一内存架构,堪称是量身定制,效率极高,性能拉满。
评测结果果然,最终进化生成的核函数在各项综合基准测试中,都展现出了显著的性能提升:
核心性能指标增益
解码速度(Decode Speed):平均提升+12.5%(标准差σ = 38.3%)
预填充速度(Prefill Speed):平均提升+14.4%(标准差σ = 17.6%)
总吞吐量(Total Throughput):平均提升+10.4%(标准差σ = 30.7%)
内存使用量(Memory Usage):平均降低+0.99%(标准差σ = 1.7%)
正确性(Correctness):保持100%的数值精度
可靠性(Reliability):零GPU错误或核函数崩溃
详细基准测试结果
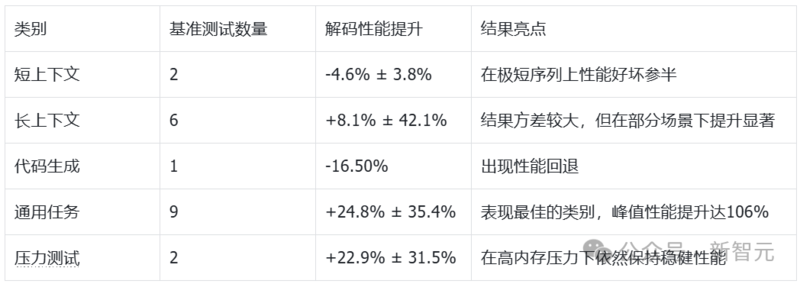
而且其中最为瞩目的是,在处理重复性模式生成任务时,OpenEvolve进化生成的核函数直接把解码速度提升了足足106%!如此一来也就充分证明了,这个核函数在应对特定类型的工作负载时,真的性能爆棚。
统计分析
总之,从统计结果来看,OpenEvolve在某些特定类型的工作负载上,确实有很强的优化能力,能挖掘出原先的手写代码难以触及的性能潜力。
在20个不同测试任务中,它在其中7个任务上提升非常明显,性能增长超过了25%,体现出了「质的飞跃」。
显著增益(>25%):7/20个基准
中等增益(5-25%):3/20个基准
性能持平(±5%):4/20个基准
性能回退(背后功臣:高鲁棒性评估系统注意,这一项目之所以能成功,有一个关键功臣就是OpenEvolve背后的评估系统。
它不是普通的跑分工具,而是专门为GPU核函数这种「硬核」代码而设计的,专为应对GPU核函数开发过程中的各种挑战。
GPU安全特性
命令缓冲区保护:自动检测Metal命令缓冲区的错误并从中恢复。
内存访问违规处理:安全地处理GPU内存访问违规。
重试逻辑:为瞬时GPU错误提供指数退避重试机制。
回退机制:当核函数彻底失败时,能够优雅地降级到备用方案。
全面的错误统计
# 评估结果示例{ “metal_safety_statistics”: { “metal_command_buffer_errors”: 0, “metal_memory_violations”: 0, “total_metal_errors”: 0, “safety_score”: 100.0 }}
正是因为这套评估系统特别稳、鲁棒性极高,OpenEvolve才敢放开手脚去尝试各种激进的优化方案,而不用担心「越改越崩」。
要知道,GPU核函数这种实验性代码本来就很容易出错,一点小问题就可能导致整个程序挂掉。
所以,有这么一套高鲁棒性的机制兜底,才让系统能放心大胆地「卷」出新花样,把性能一步步推上去。
技术深度剖析
面向GPU核函数的进化架构
此外,项目的成功也离不开OpenEvolve中多个组件的协同工作:
智能代码标记:通过特定标记,确保进化过程仅针对Metal核函数源代码,同时完整保留与MLX框架的集成代码。
# EVOLVE-BLOCK-STARTkernel_source=”””// 仅此块内的Metal核函数代码会被进化”””# EVOLVE-BLOCK-END
富含上下文信息的提示词:为进化提供的提示词包含了性能数据、硬件规格和优化方向指南。
多目标评分机制:在性能、正确性和安全性等多个目标之间进行权衡评分。
特定硬件验证:所有测试和优化都针对Apple Silicon硬件进行。
面向GPU优化的提示词工程
与此同时,为进化过程提供的提示词,也给OpenEvolve提供了至关重要的上下文信息:
## 硬件上下文信息-Apple Silicon M-series GPU with unified memory(GPU为Apple Silicon M系列,采用统一内存架构)-SIMD width: 8 elements optimal for vec(最佳SIMD宽度为8个元素,适用于vec类型)-Thread group size: 32 threads for optimal occupancy(最佳线程组大小为32线程,以达到最高硬件占用率)## 优化目标-Minimize memory bandwidth usage(最小化内存带宽占用)-Maximize SIMD utilization(最大化SIMD指令利用率)-Exploit GQA 40:8 head structure(充分利用GQA模型的40:8头结构特性)-Maintain numerical stability(保持数值计算的稳定性)## 性能基线Current decode speed: 140.6 tokens/sec(当前解码速度:140.6 token/秒)Target improvement: >5% speedup required(目标:需要>5%的速度提升)
更深远的影响
总之,本次对GPU核函数的成功优化,揭示了以下几点重要原则:
1. 专业知识的自动化探索与发现
OpenEvolve发现的优化策略,涵盖了众多需要深厚专业知识的领域:
Apple Silicon的架构细节
Metal编程语言的精妙之处
注意力算法的各种变体
内存访问模式的优化
这些领域知识并非由人类工程师直接提供,而是在进化探索的过程中自主涌现的。
2. 面向特定硬件的自适应优化
最终的优化方案是为Apple Silicon硬件量身定制的,这就表明,OpenEvolve具备自动发掘、利用特定硬件特性的能力。
3. 算法层面的创新
进化过程发现的「两阶段在线Softmax(two-pass online softmax)」算法,本身就是一项新颖的技术贡献,应用潜力已经远远超出了本次实验的特定场景。
4. 具备投产应用的价值
这些优化并非「纸上谈兵」,而是在真实的Transformer推理负载中能带来显著性能提升的实用技术,完全具备在生产环境中部署的价值。
核心技术架构升级
并且,自项目启动以来,Sharma已对OpenEvolve的核心能力进行了显著增强:
可复现性(Reproducibility)
通过完全确定性的进化过程,保证科研级别的可复现性。
random_seed:42 # 确保每次运行结果完全一致
可视化(Visualization)
提供可交互的进化树视图,支持实时性能追踪。
python scripts/visualizer.py
岛屿进化(Island Evolution)
通过种群迁移实现并行进化,以增强解空间的探索能力。
database:num_islands:5migration_interval:25
稳健的检查点机制(Robust Checkpointing)
支持自动保存进度,并能从中断处恢复进化会话。
快速开始
所以,你准备好亲自上手,挑战GPU核函数优化或其他复杂难题了吗?
输入以下代码,就可以快速开始了:
# 克隆仓库gitclonehttps://github.com/codelion/openevolve.gitcdopenevolve# 安装依赖pip install -e .# 运行MLX核函数优化示例cdexamples/mlx_metal_kernel_optpython openevolve-run.py initial_program.py evaluator.py –iterations 25
如果想进一步了解更深入的信息,建议仔细阅读一下这几个文档。
GPU内核优化指南:https://github.com/codelion/openevolve/tree/main/examples/mlx_metal_kernel_opt
通用教程:https://github.com/codelion/openevolve#getting-started
配置参考:https://github.com/codelion/openevolve/tree/main/configs
参考资料:
https://huggingface.co/blog/codelion/openevolve-gpu-kernel-discovery



{kind=link}